Objective
Determine the best data store file format for storing, updating and retrieving financial market data. The typical process would be to retrieve a complete trading days minute bars at the end of the day, append those to the existing data set, and then retrieving the data for analysis.
The tests look to mimic the process of storing 1min bar time series for financial data that is (1) updated daily with new data, including updating prior days in case there are error corrections by the data provider (2) using either the data set or a subset of that time series data for analysis or trading.
For this analysis we value speed over disk space, choosing the fastest solution regardless of file size.
Summary
For the use case of these tests, it is a choice between HDF on a local file system and ArcticDB on S3. If using one machine for both the storage and retrieval of the data, then HDF on a local file system and ArcticDB are both good choices when the amount of data is greater than 10 years of 1min bars, HDF is better when there is less data. If the reading or writing of data is done over the network, then ArcticDB on S3 is the best choice.
Methodology
The analysis uses 1min bar tick data is with a row for every 1 minute with 5 columns (open, high, low, close, volume). The number of observations is the number of years * 252 days in a year * 6.5 hours in a stock trading day * 60 minutes in an hour. So for example the 10y sample will have a data frame with 982,800 rows with 5 columns.
Operations that are tested are:
INSERT – Writes (“inserts”) the entire time series into the data store
SELECT – Reads (“selects”) the entire time series from the data store
UPDATE – Upserts (“updates”) data to the time series and re-saves to the data store. This includes both overwriting existing data (2 days) and appending new data (3 days)
SELECT_CUT – Reads (“selects”) a small sub-set, 5 days, of the data from the data store
For each combination of data store format and operation 25 runs are performed.
Data Store Format Options
The competing formats tested are:
- ArcticDB
- HDF
- Feather
- Parquet
For each format multiple compression and other methods were tested and compared.
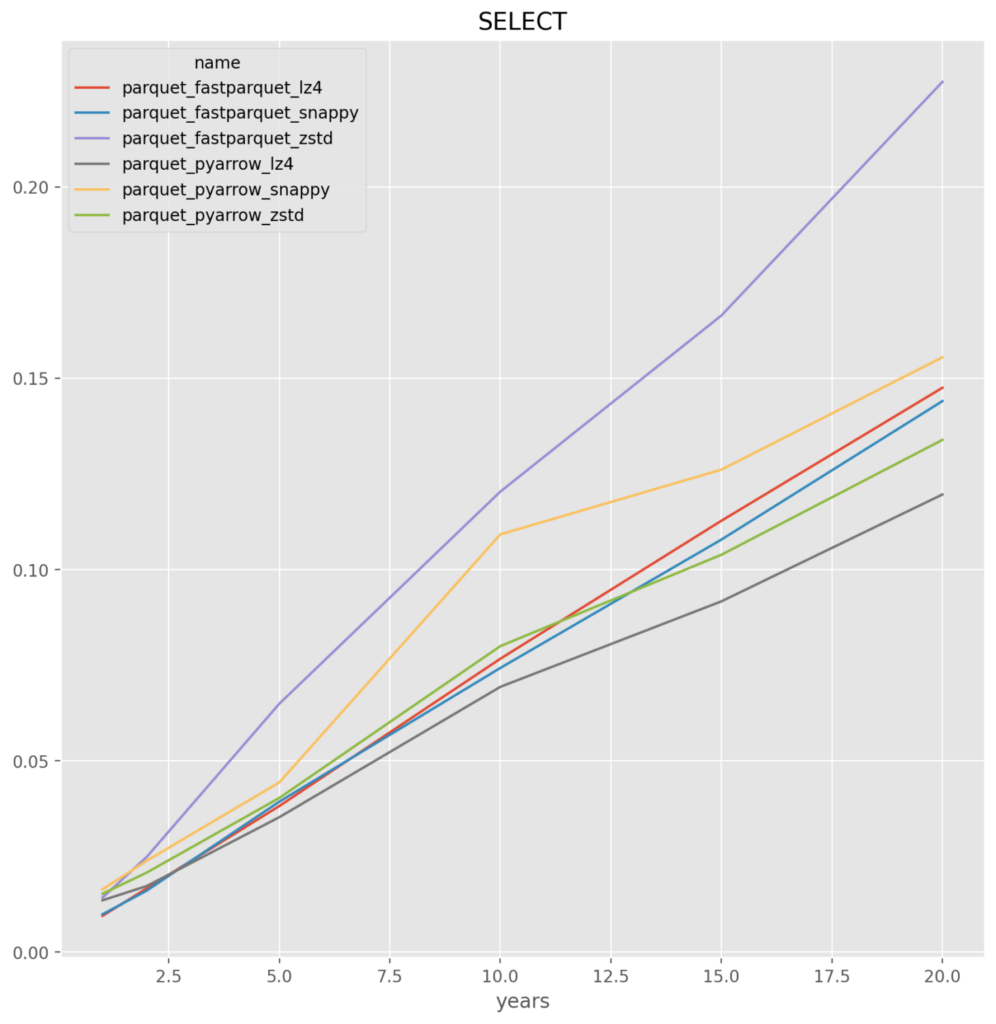
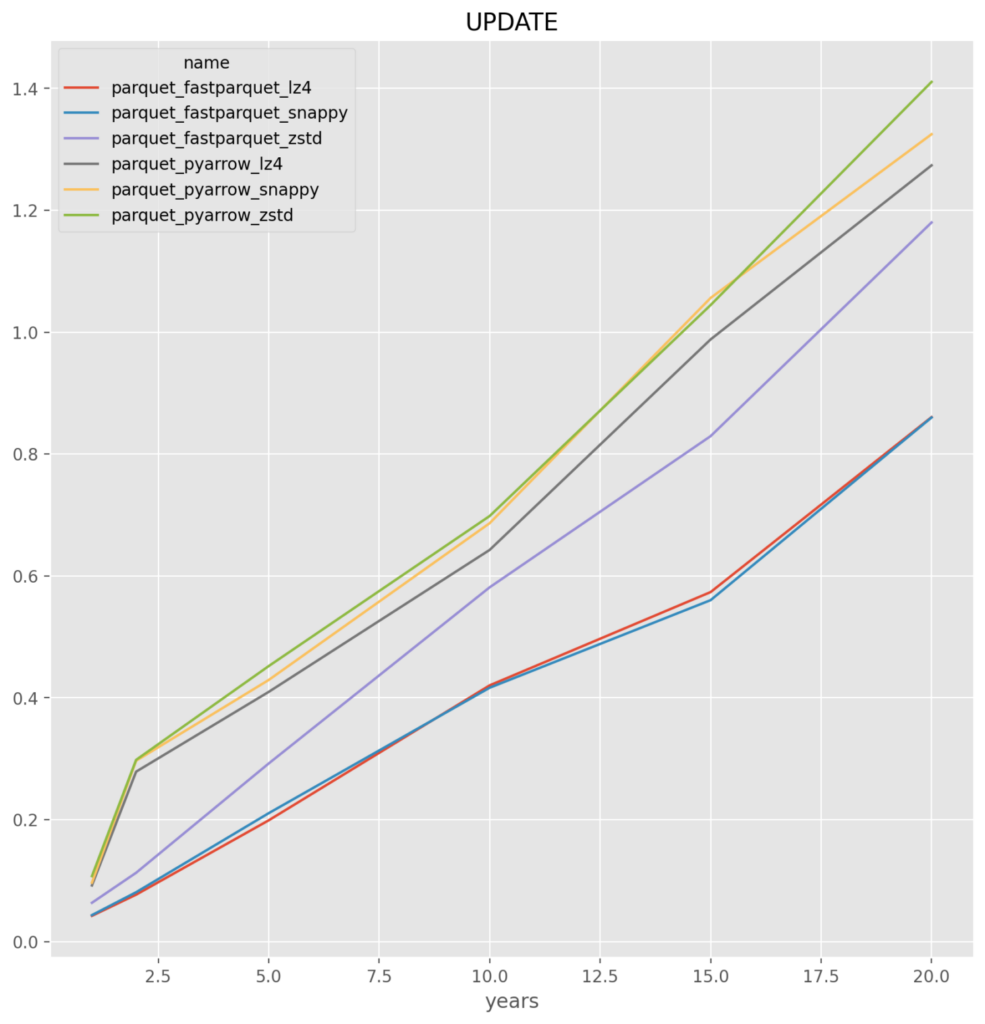
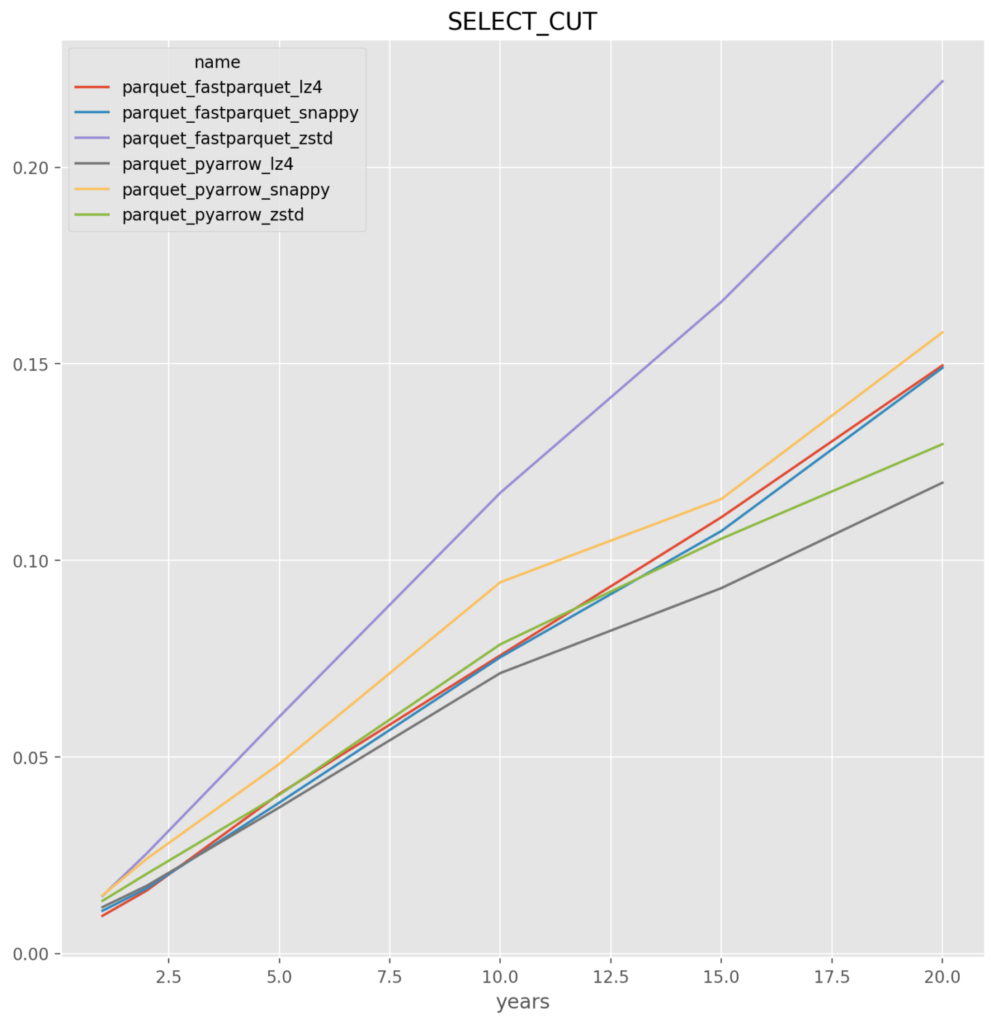
*Note* that the parquet and feather file formats failed on runs greater than 25 runs as there is known memory issues. For this reason alone feather and parquet should be rejected as an optimal solution. This is a known issue that has to do with the memory consumption when reading or writing multiple large data frames.
Machine & Library Specs
The tests were performed on a Digital Ocean VM with the following specs:
- 4 “Regular” Intel CPUs
- 8GB of RAM
machine
------------------------
platform.architecture()[0]='64bit'
platform.machine()='x86_64'
platform.processor()='x86_64'
platform.system()='Linux'
platform.release()='5.15.0-87-generic'
platform.version()='#97-Ubuntu SMP Mon Oct 2 21:09:21 UTC 2023'
platform.platform()='Linux-5.15.0-87-generic-x86_64-with-glibc2.35'
python
------------------------
python = sys.version_info(major=3, minor=11, micro=4, releaselevel='final', serial=0)
libraries
------------------------
pandas.__version__='2.0.3'
tables.__version__='3.9.1'
pyarrow.__version__='14.0.1'
fastparquet.__version__='2023.10.1'
arcticdb.__version__='4.1.0'
Read/Write Functions
For HDF, Parquet and Feather the pandas to_* and read_* functions were used. For Arctic their native read() and write() functions were used.
Results Summary
Local File System
When all file stores are on the local file system the clear winner is ArcticDB because of its performance on updates and select_cut, which makes sense because the other file formats are not optimized for this and require a read and/or write of the entire data series regardless of what portion is being updated or read.
*BUT* note that ArcticDB recommends against using the local data store option either over a local network or with multiple processes on the same machine (https://github.com/man-group/ArcticDB/issues/488) as such we analyze below the comparison of the ArcticDB S3 option versus the local file store option for the other file store formats.
- arctic, hdf and feather perform in-line for insert and select where the entire data set is written and read. With an advantage to arctic on the writes. Not surprising given the storage format, arctic well outperforms on the UPDATE and SELECT_CUT
- parquet – across the board for either fastparquet or pyarrow it is the worst, and given the implementation issues they are dropped
*NOTE* All y-axis are in seconds
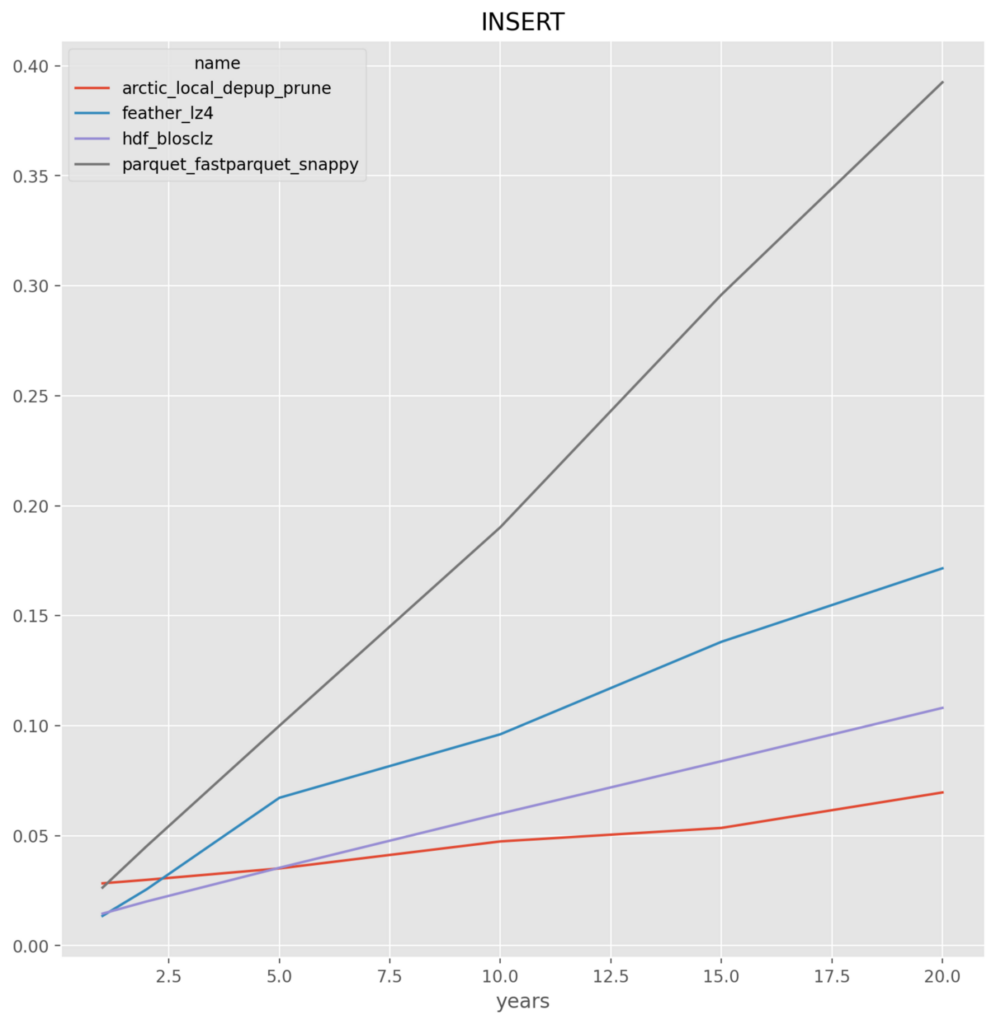
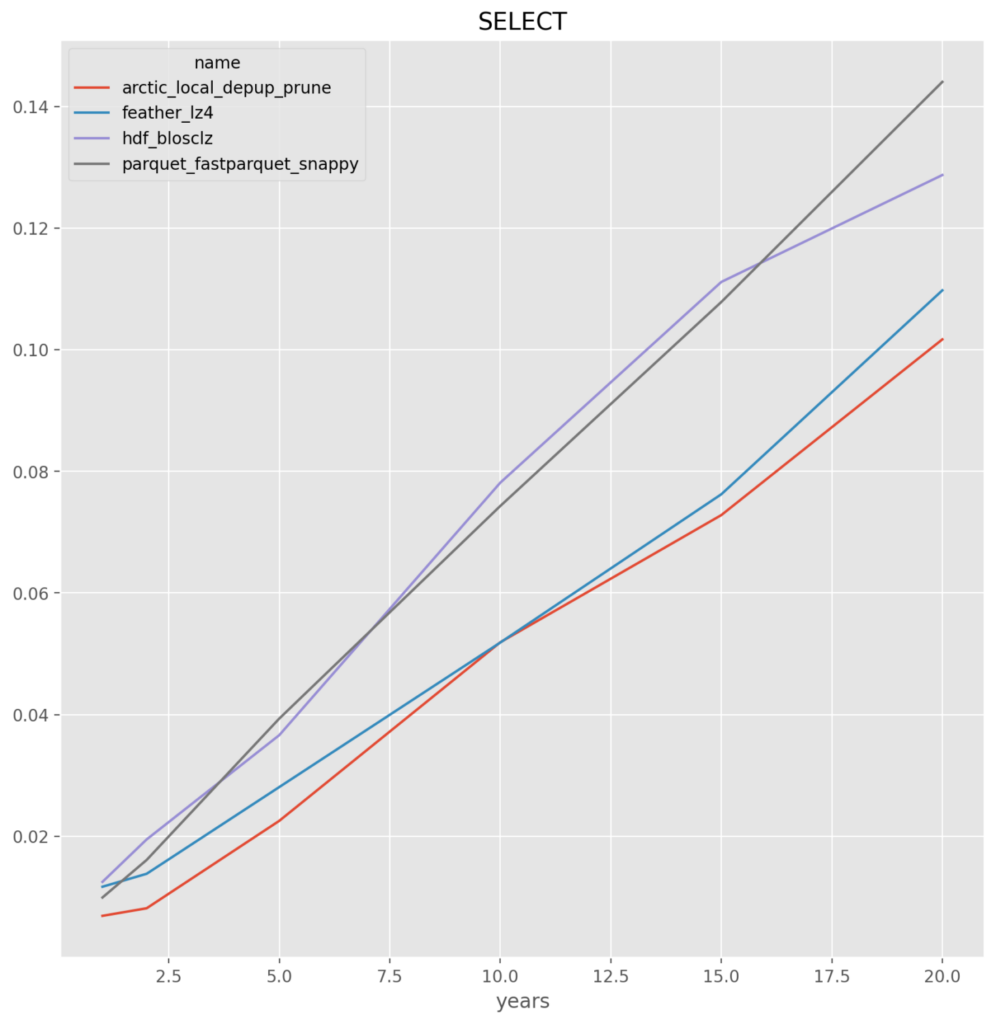
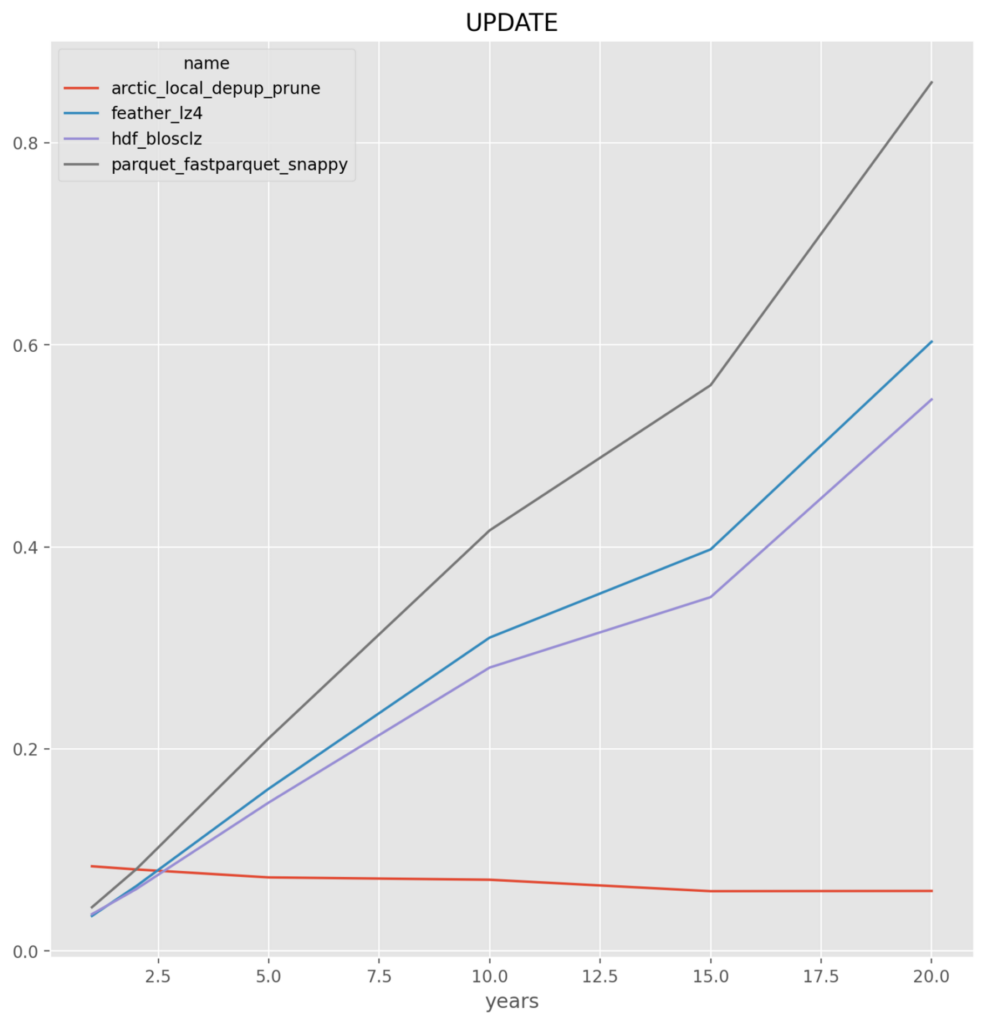
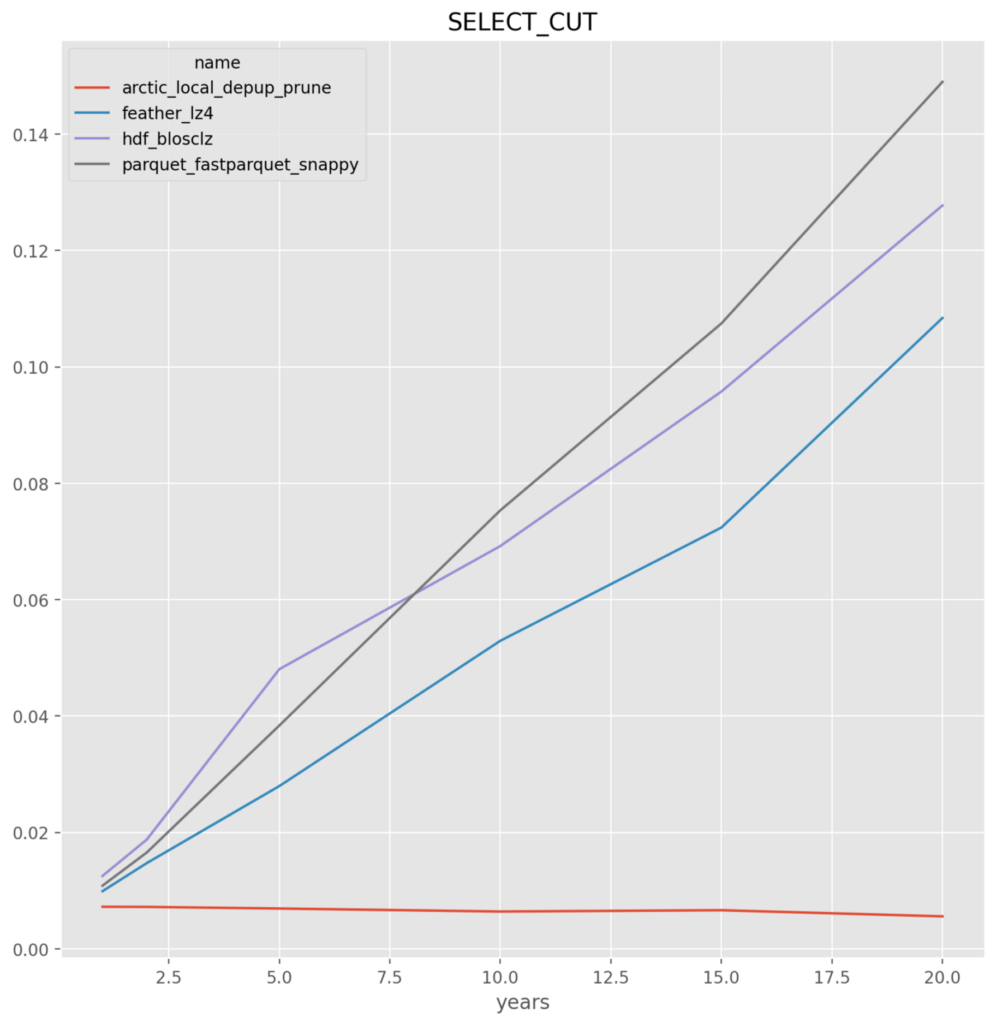
Local File System for all except Arctic on S3
Comparing the S3 storage version of ArcticDB
- For large data insert and select the local store HDF and Feather outperform.
- For the UPDATE and SELECT_CUT the ability of Arctic to not require reading and writing the entire dataset gives it consistent performance and faster at larger number of year.parquet – across the board for either fastparquet or pyarrow it is the worst, and given the implementation issues they are dropped
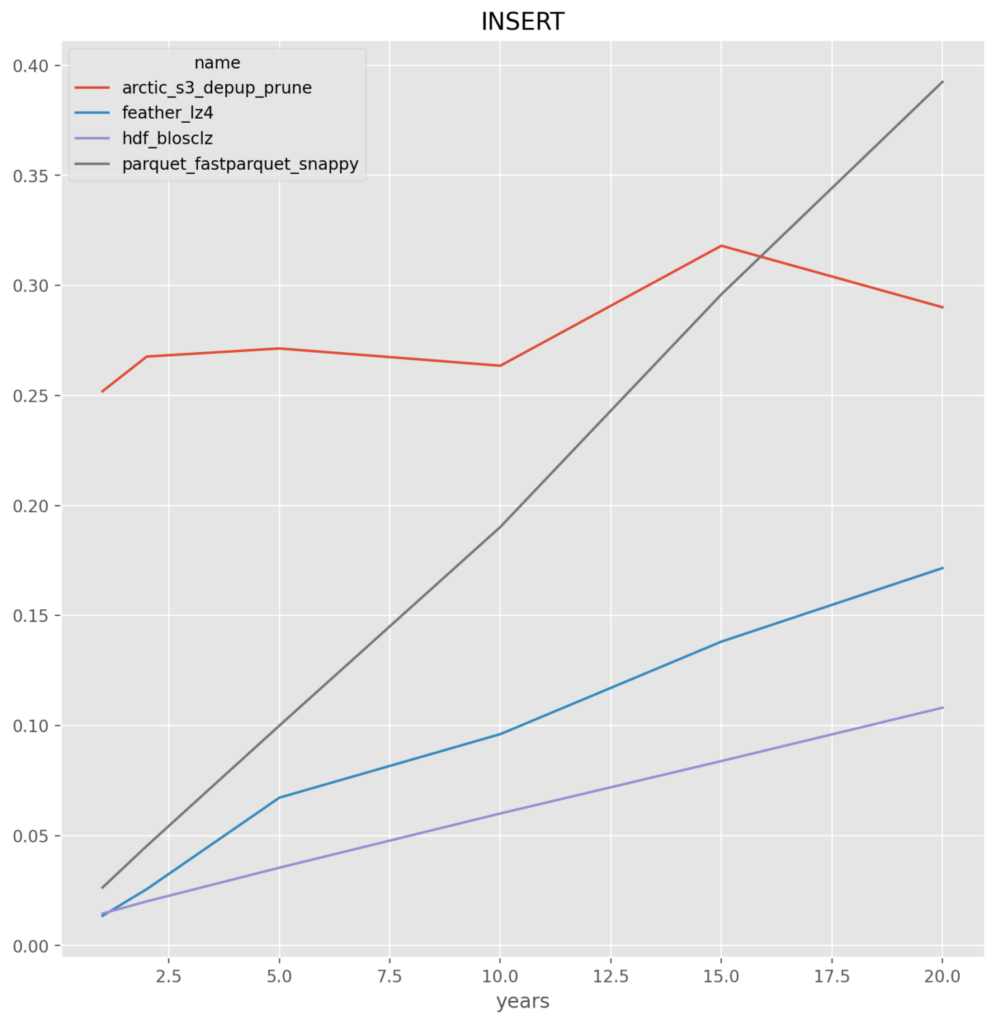
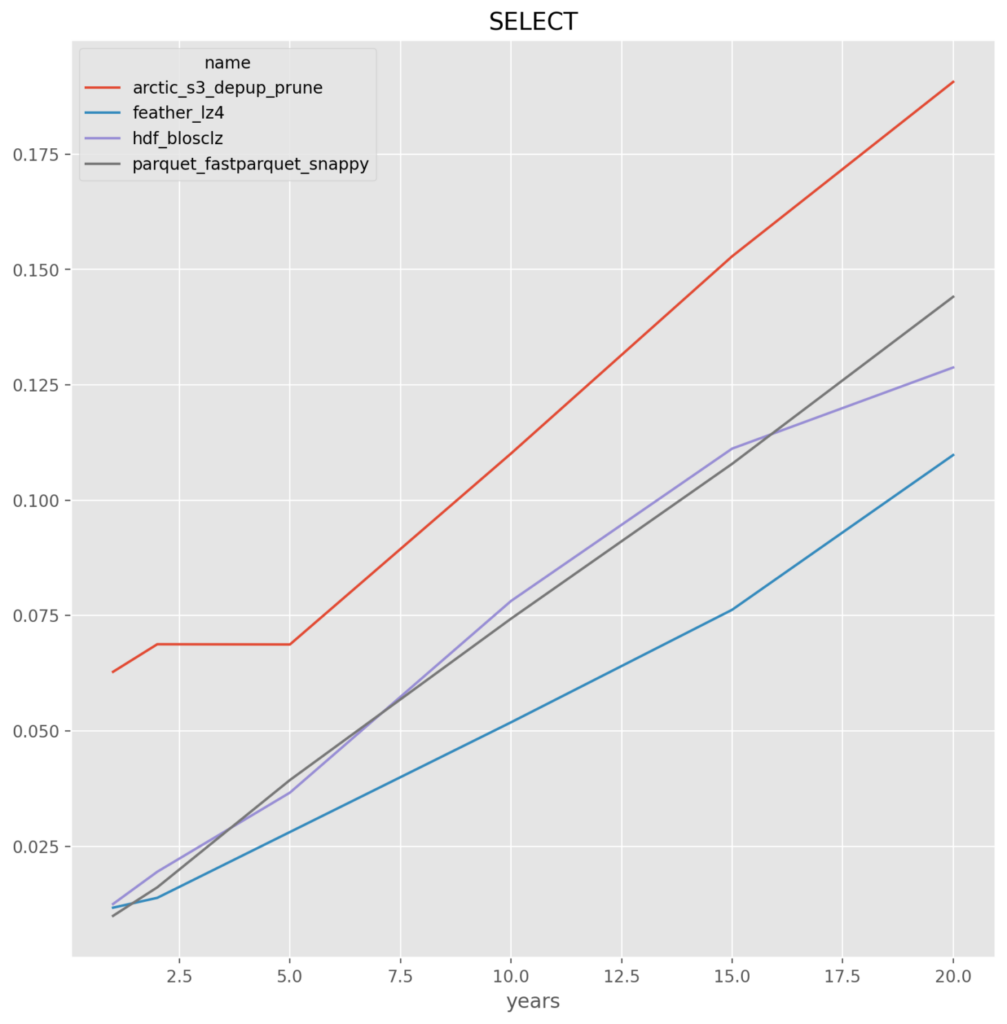
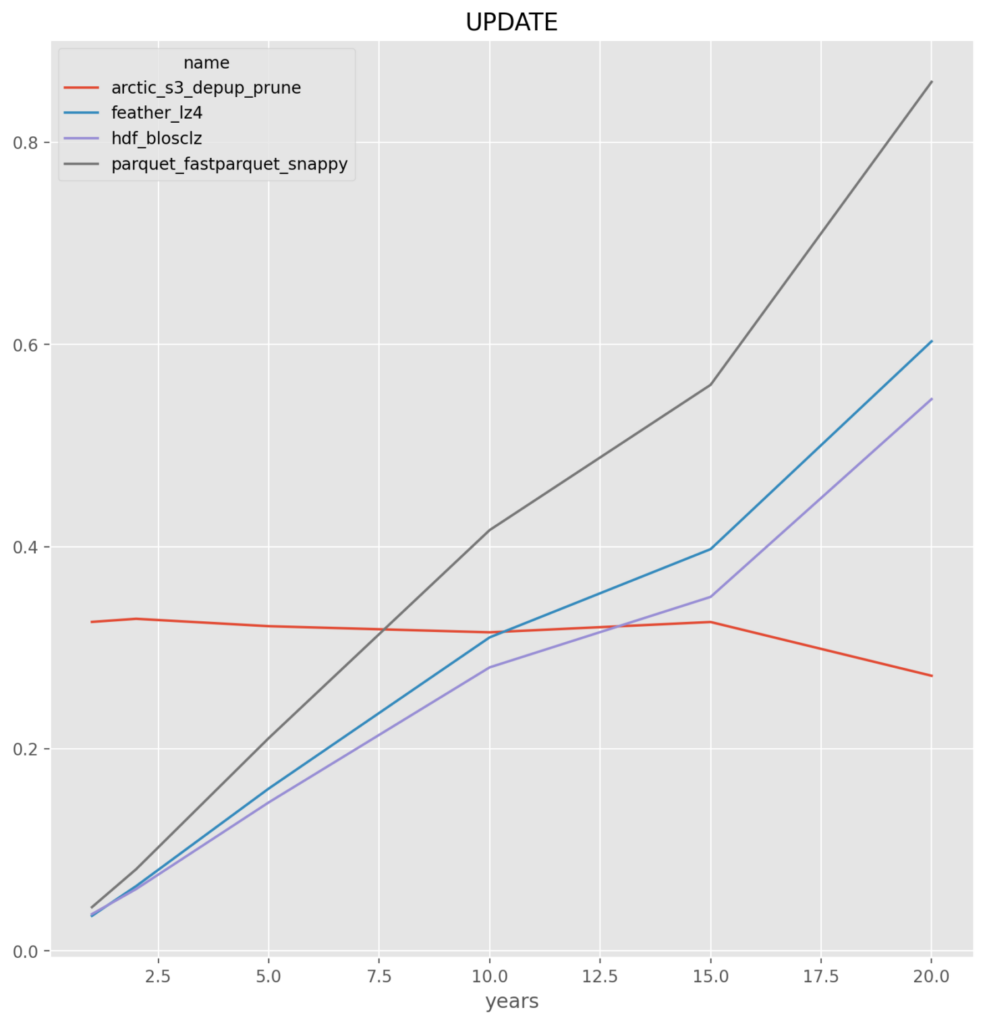
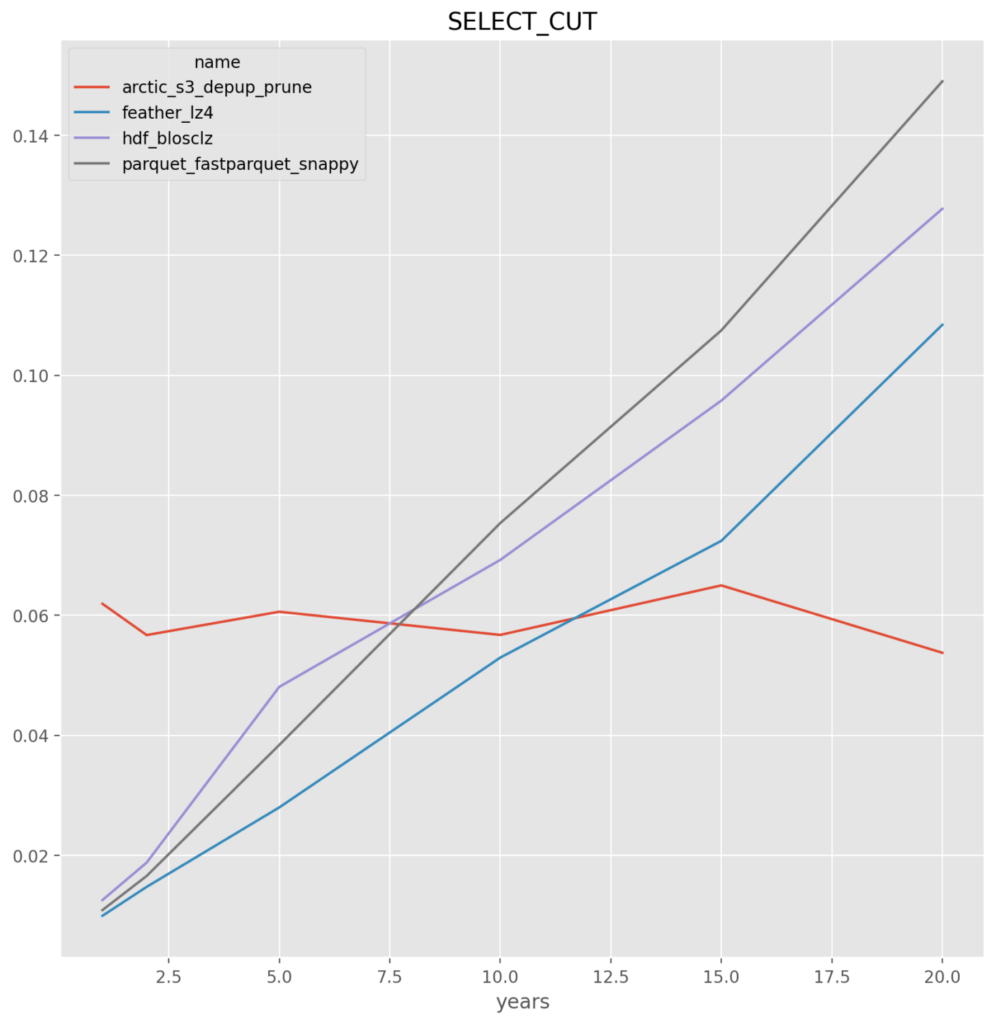
Individual Format Results
First we run inside each file type to find the best set of parameters for that file type, then we will run the file types versus each other.
Feather
feather_lz4 – It is very close between this and uncompressed, but for the slight savings in file size and thus the saving going over the network, this compressed format is chosen
Parquet
fastparquet_snappy – It was very close with fastparquet_lz4. The challenge is that there appears to be a problem where fastparquet does not work when run at a large number of files, for example the test at 50 file run crashes. If so then the backup would be pyarrow_lz4
HDF
From prior analysis the blosclz is the best compression
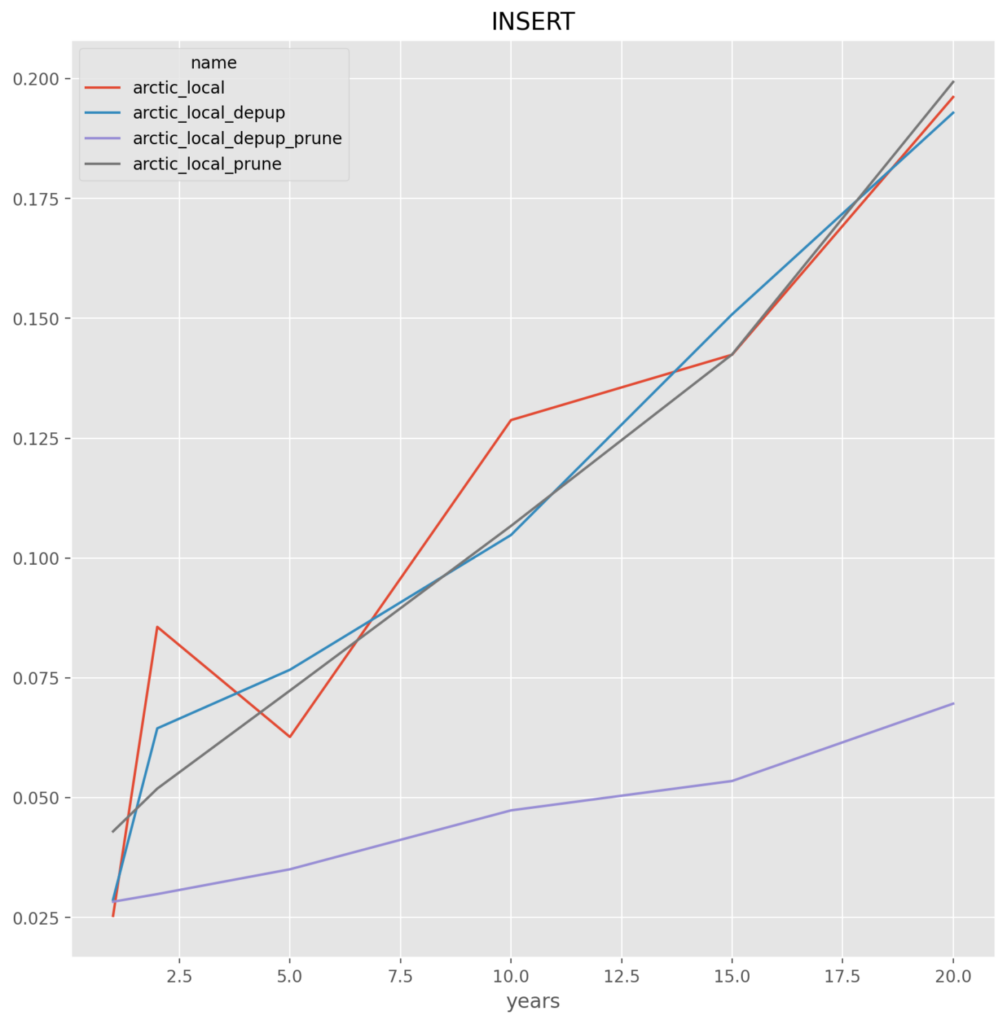
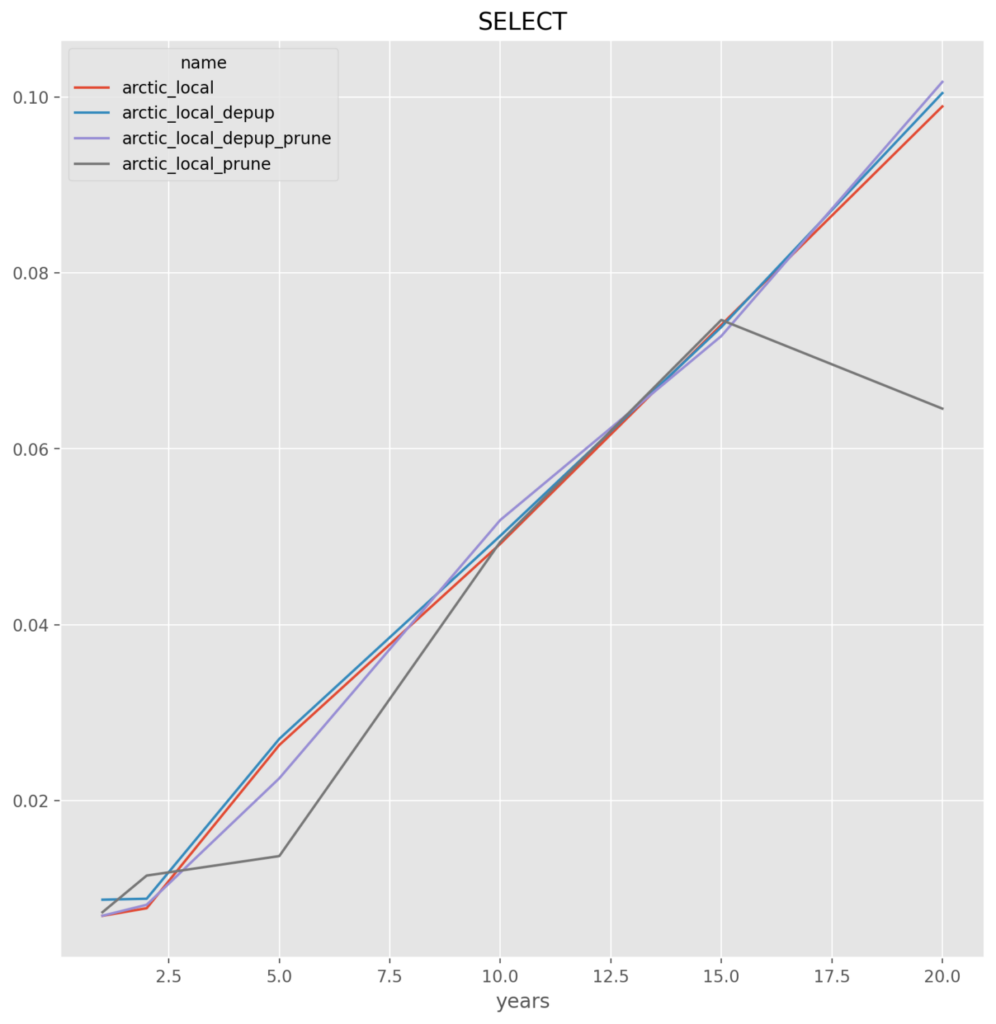
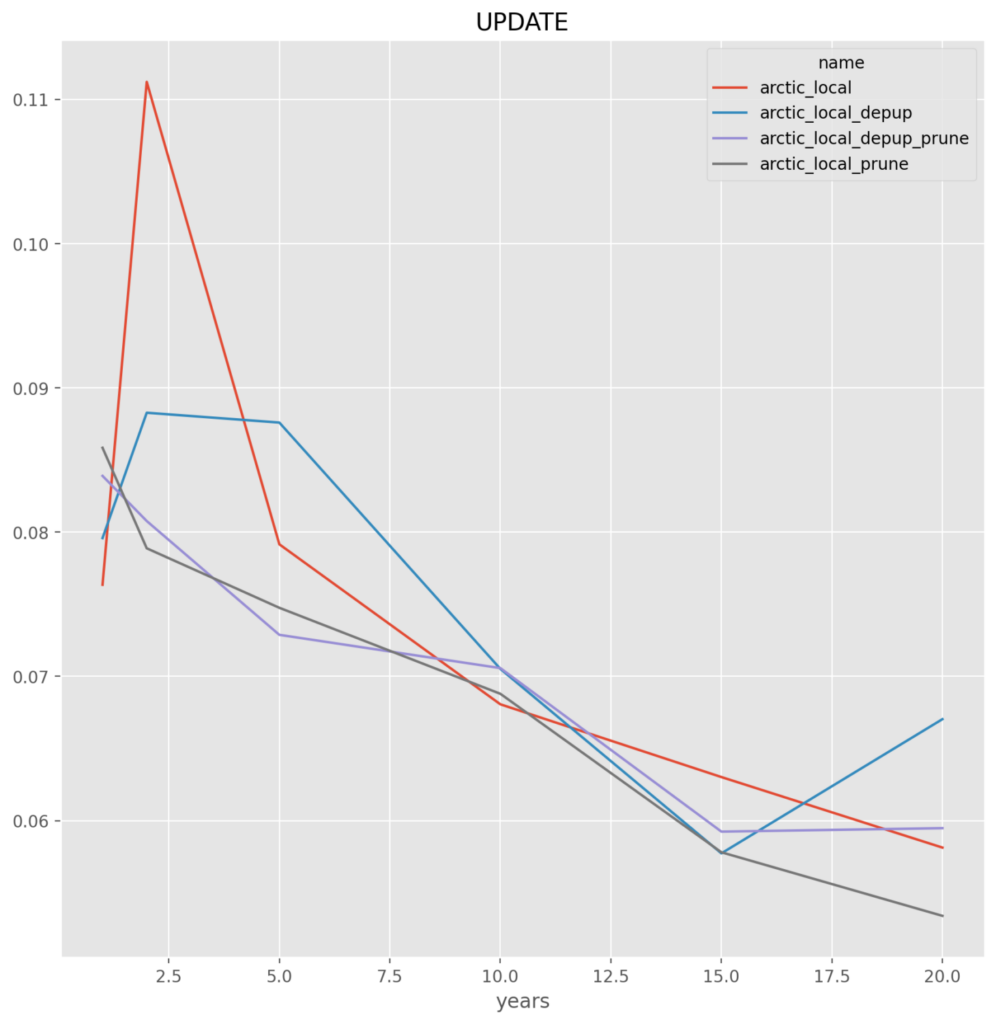
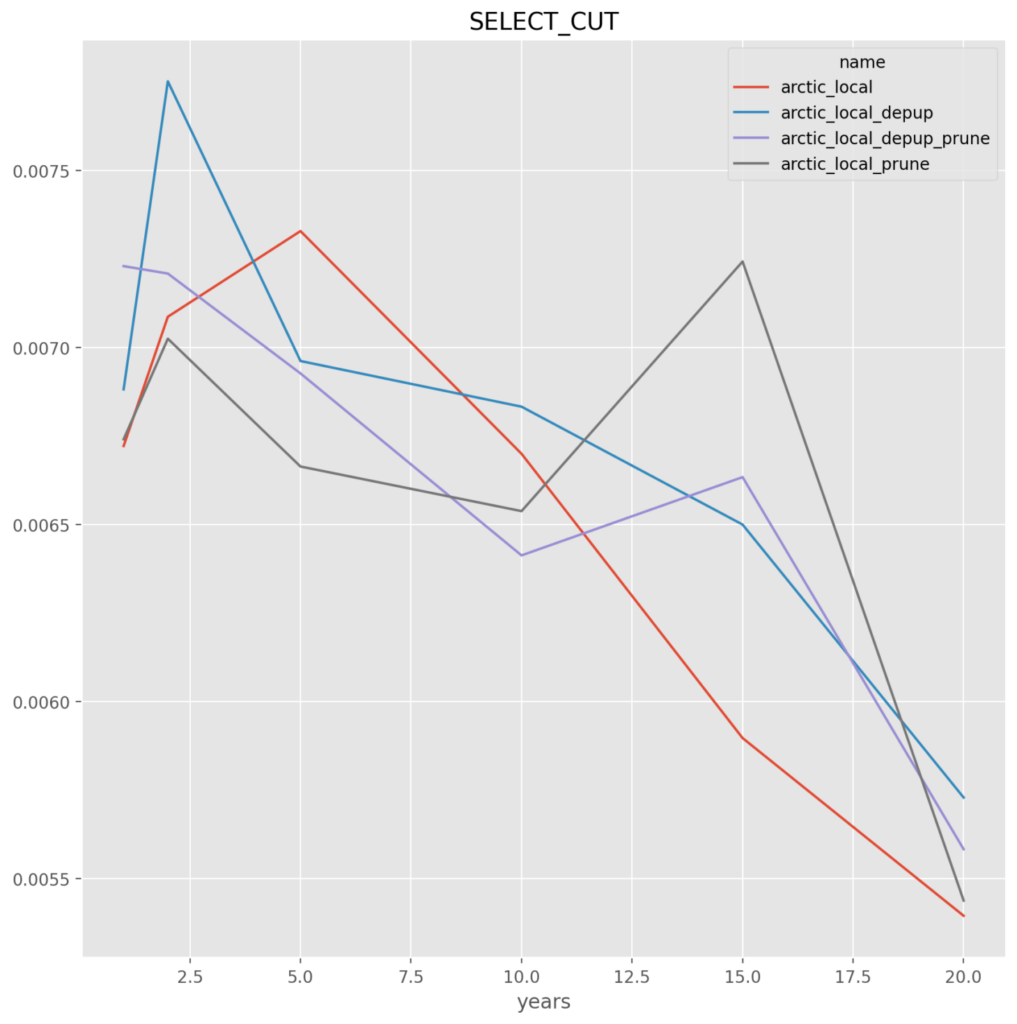
Arctic_Local
depup_prune – The options that retain the least amount of duplicate data appears to be the best choice, which is also good as it will reduce the backup size requirements
Feather
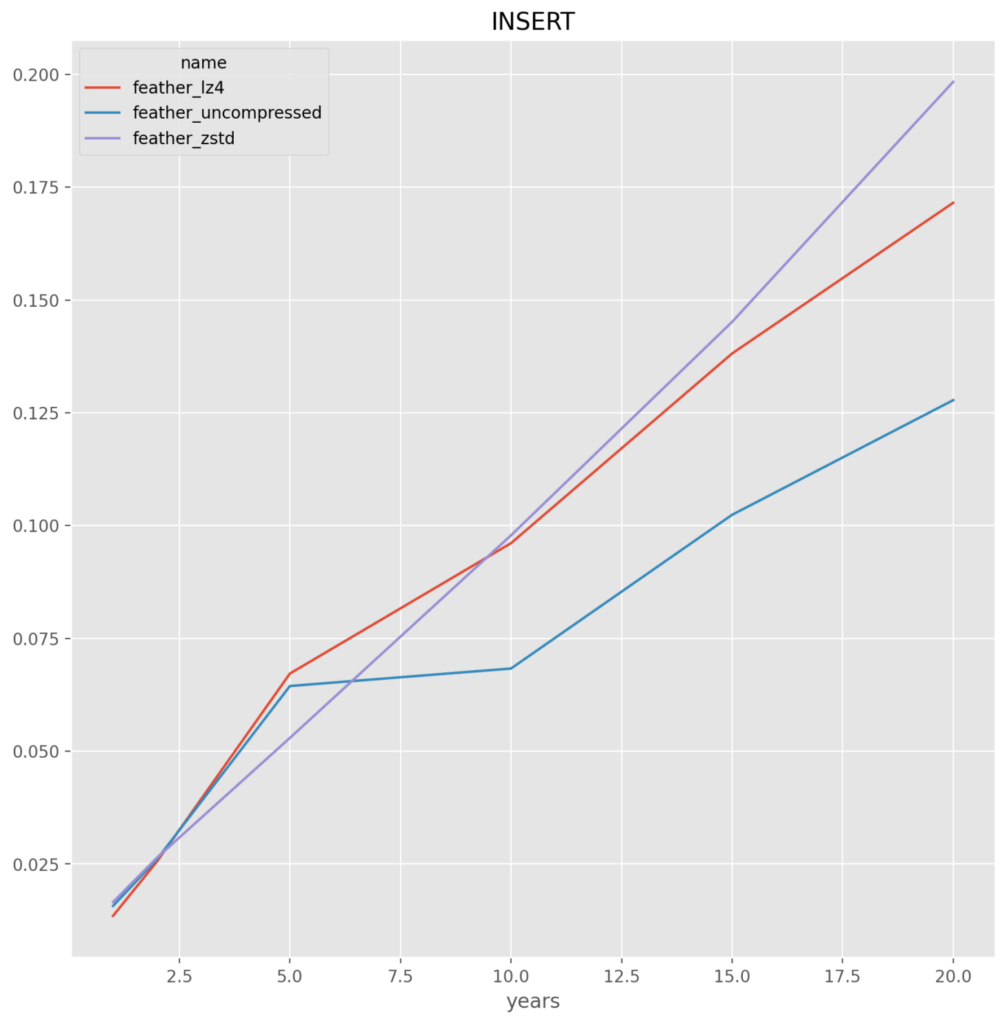
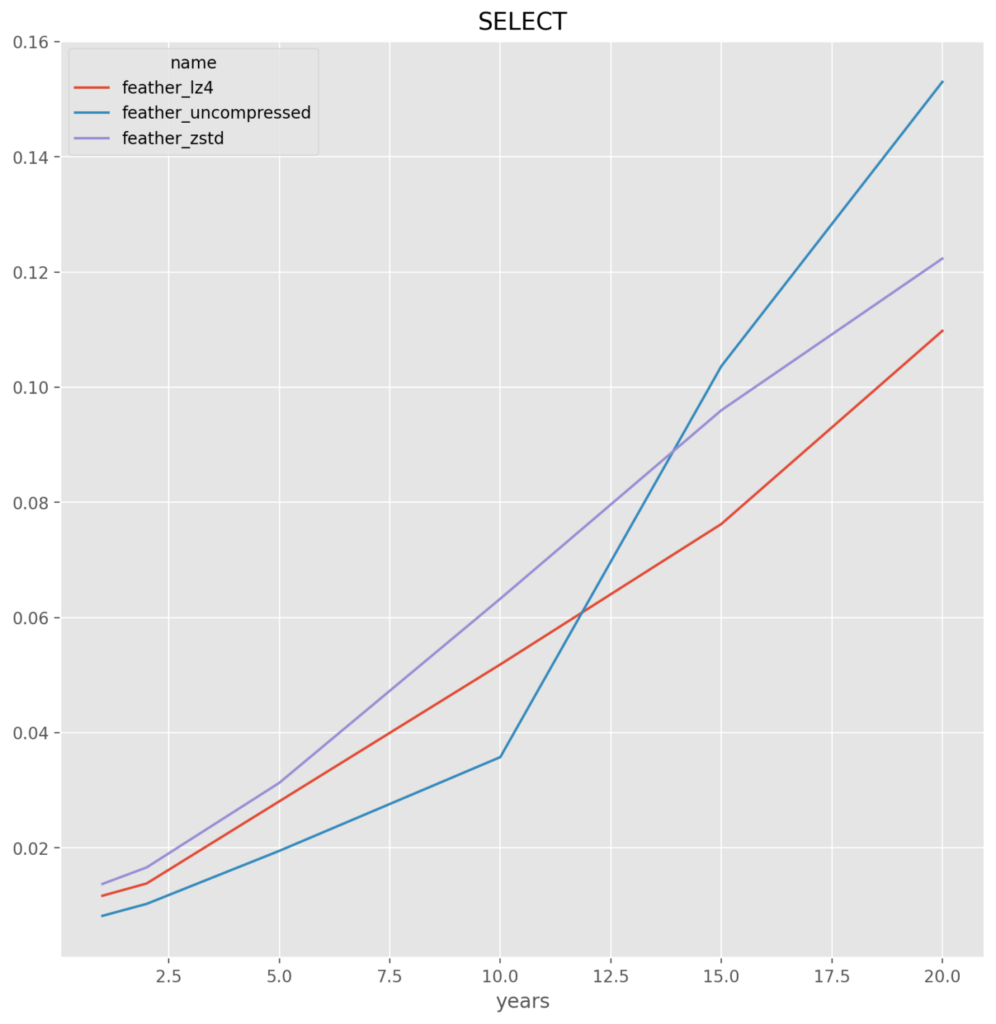
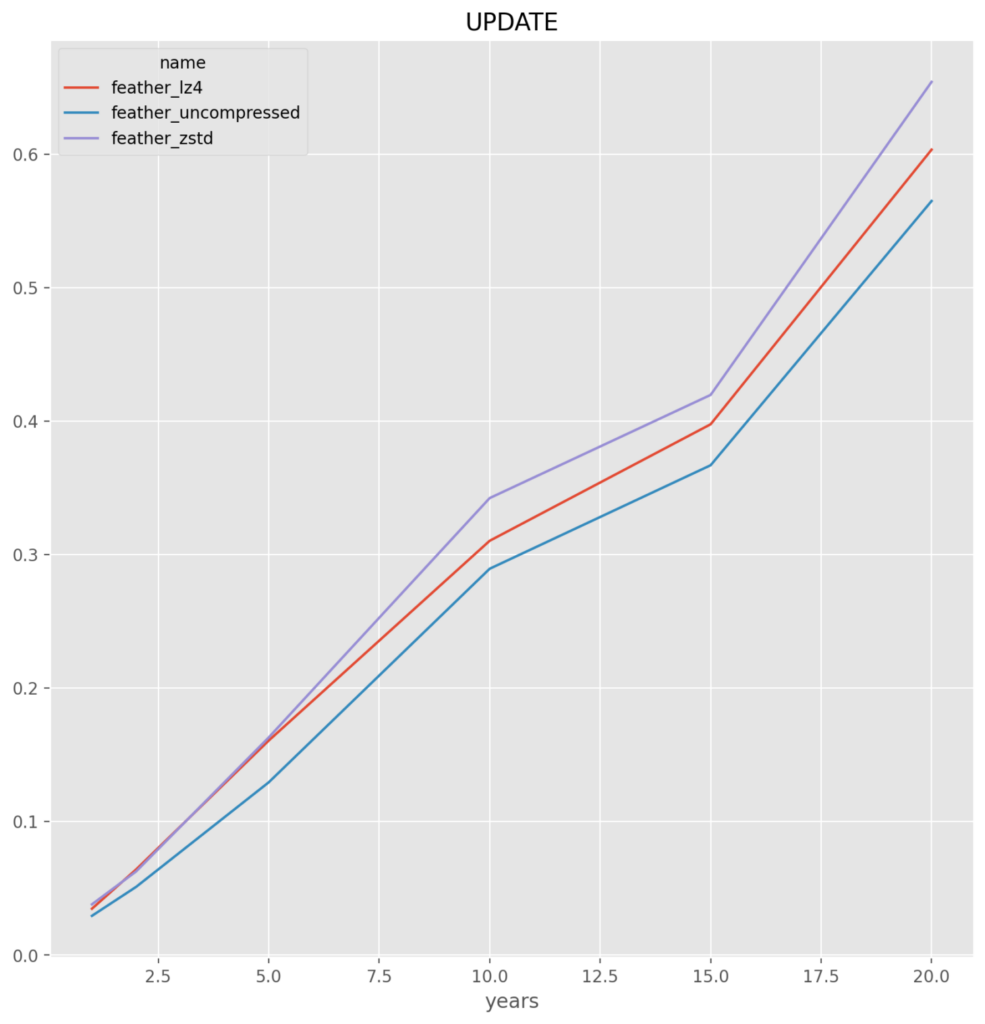
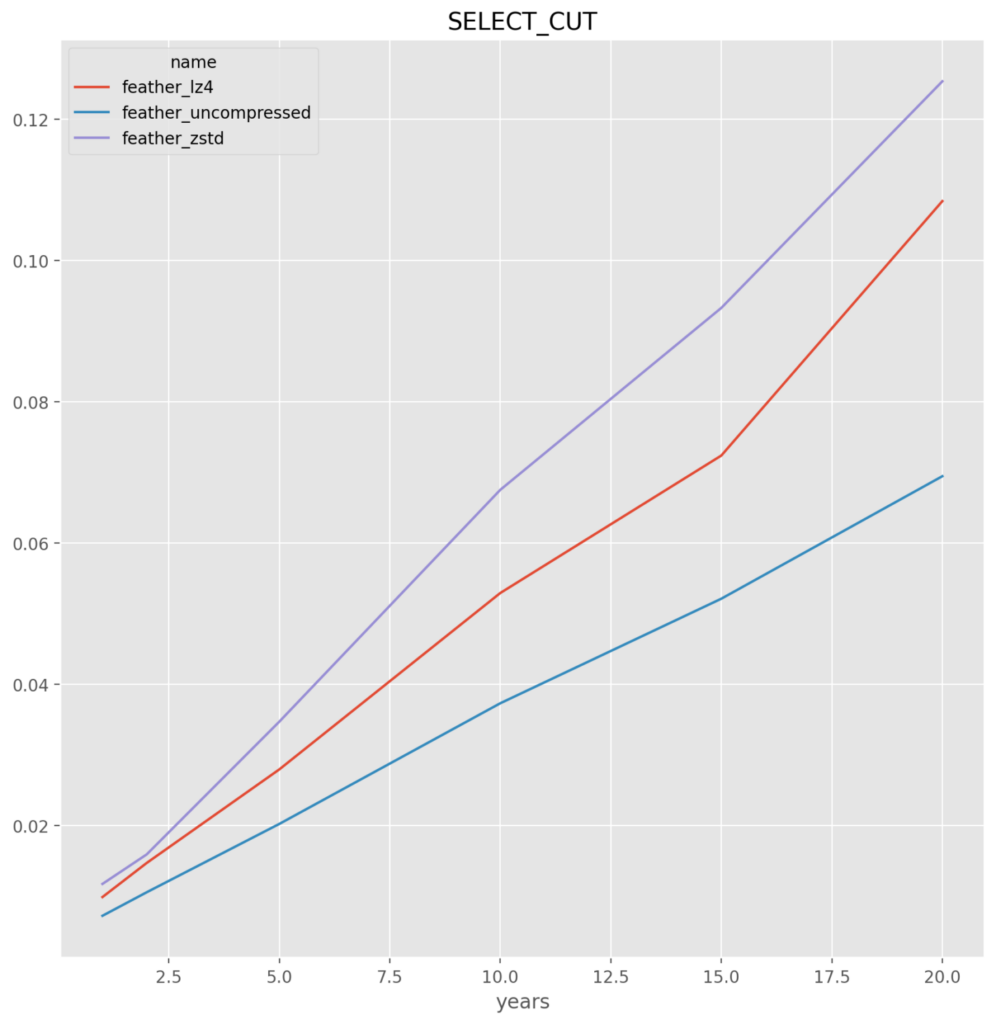
Parquet
Arctic